Unicode 対応
Unicode について
Unicode (ユニコード) は,世界中のすべての文字を扱うことを目的として作られた,文字コードの規格です。
2014 年現在,約 11 万もの文字が Unicode に収録されています。
Unicode の文字符号化方式には,主に次のようなものがあります。
- UTF-8: 1 文字を最小 8 ビット,最大 32 ビットで表現。
- UTF-16: 1 文字を最小 16 ビット,最大 32 ビットで表現。
- UTF-32: 1 文字を 32 ビットで表現。
Windows では,Win32 世代から Unicode がサポートされています。
Windows が採用している Unicode の文字符号化方式は,UTF-16 です。
ワイド文字
C の文字型には,char 型の他に,wchar_t 型 (ワイド文字) が存在します。
漢字など 1 字を表現するのに複数バイト必要な文字は,char 型では複数文字分の領域が必要ですが,wchar_t 型では 1 字分の領域で表現できるようになります。
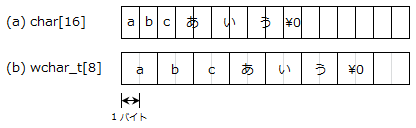
char 型は標準規格で 8 ビットと決まっていますが,wchar_t 型は処理系によって 16 ビットだったり 32 ビットだったりします。
Windows はワイド文字に UTF-16 を採用しているので,wchar_t 型のサイズは 16 ビットです。
ワイド文字,ワイド文字列のリテラルには,次のように接頭辞 L が付きます。
| ワイド文字 | L'a' |
|---|---|
| ワイド文字列 | L"hello" |
次のプログラムは,ワイド文字列を扱うプログラムの例です (UNIX でもコンパイルできます)。
fprintf の代わりに fwprintf,strlen の代わりに wcslen を使っています。
// ソースコードは UTF-8 で保存
#include <stdio.h>
#include <wchar.h>
int main(void)
{
wchar_t wstr[] = L"Hello こんにちは 你好 안녕하세요";
FILE *fp;
// ファイルを UTF-8 で書き込み用に開く
if ((fp = fopen("wchar_test.txt", "w, ccs=UTF-8")) == NULL) {
fprintf(stderr, "Could not open wchar_text.txt\n");
return 1;
}
fwprintf(fp, L"wstr: %s\n", wstr);
fwprintf(fp, L"wcslen(wstr): %d\n", wcslen(wstr)); // 文字数
fwprintf(fp, L"sizeof wstr: %d\n", sizeof wstr); // バイト数
fclose(fp);
return 0;
}<b>[出力]</b>
wstr: Hello こんにちは 你好 안녕하세요
wcslen(wstr): 20
sizeof wstr: 42
ワイド文字関連の関数が含まれるヘッダファイルには,wchar.h と wctype.h があります。
上のプログラムで使用した fwprintr, wcslen は wchar.h に宣言されています。
汎用の文字型
Win32/Win64 API の基本的な文字型は,CHAR 型, WCHAR 型, TCHAR 型です。
それぞれの型は,次のように定義されています。
typedef char CHAR
typedef wchar_t WCHAR
#ifdef UNICODE
typedef wchar_t TCHAR
#else
typedef char TCHAR
#endifまた,Visual C++ のランタイムライブラリ (CRT) にも同様の型が定義されています。
こちらはヘッダファイル tchar.h を読み込むことで利用できます。
#ifdef _UNICODE
typedef wchar_t _TCHAR
#else
typedef char _TCHAR
#endifUNICODE 等の記号定数は,文字セット(*1) の設定に応じてコンパイラが定義します(*2)。
文字セットの設定には,次のような種類があります。
| 設定 | 対応する文字コード | 定義される記号 |
|---|---|---|
| 設定なし | ASCII | なし |
| マルチバイト文字 | Shift_JIS など | _MBCS |
| Unicode | Unicode | UNICODE, _UNICODE |
マルチバイト文字とは,日本で言えば Shift_JIS のような文字コードのことで,1 文字が 2 バイト以上になりうる文字コードを言います。
(*1) ここでは Visual Studio の表記に合わせて "文字セット" という用語を使っていますが,本来は "文字コード" くらいの言葉の方が適切だと思います。
(*2) 文字セットの設定は,ソリューションエクスプローラで対象のプロジェクトを右クリック - [プロパティ] を開いた上で,[構成プロパティ] - [全般] より行うことができます。

汎用の関数
メッセージボックスを表示する関数 MessageBox の実体は,MessageBoxA (ASCII 版), MessageBoxW (ワイド文字版) という 2 種類の関数です。
ソースコード中の識別子 MessageBox は,UNICODE が定義されていれば MessageBoxW に,未定義であれば MessageBoxA に置換されます。
#ifdef UNICODE
#define MessageBox MessageBoxW
#else
#define MessageBox MessageBoxA
#endif
// ASCII 版
int MessageBoxA(HWND, LPCSTR, LPCSTR, UINT);
// ワイド文字版
int MessageBoxW(HWND, LPCWSTR, LPCWSTR, UINT);このように,文字列を扱う Windows API 関数の多くは UNICODE の定義の有無に応じて関数名の置換を行っています。
また,Visual C++ のランタイムライブラリも,同様にして _MBCS, _UNICODE の定義の有無によって,関数名の置換を行っています。次はその一例です。
#ifdef _UNICODE
#define _tcscmp wcscmp
#else
#ifdef _MBCS
#define _tcscmp _mbscmp
#else
#define _tcscmp strcmp
#endif
#endifCRT ライブラリには,C/C++ の標準規格に存在する関数と,Visual C++ 独自の関数とが混在しています。
一部の関数の名前がアンダースコアで始まっているのは,その関数が Visual C++ 独自の関数であることを示すためです。
主な文字列操作関数の対応関係は,次の表の通りです。
VC++ CRT の関数は tchar.h をインクルードすることで利用できます。
| Windows API | VC++ CRT | 備考 | |||
|---|---|---|---|---|---|
| 汎用関数 | 汎用関数 | 等価な関数 | 既定 | _MBCS | _UNICODE |
| lstrcat | _tcscat | strcat | _mbscat | wcscat | |
| - | _tcsncat | strncat | _mbsnbcat | wcsncat | |
| lstrcmp | _tcscmp | strcmp | _mbscmp | wcscmp | |
| - | _tcsncmp | strncmp | _mbsncmp | wcsncmp | (*1) |
| - | _tcsnccmp | strncmp | _mbsnbcmp | wcsncmp | (*1) |
| lstrcpy | _tcscpy | strcpy | _mbscpy | wcscpy | |
| lstrcpyn | _tcsncpy | strncpy | _mbsnbcpy | wcsncpy | |
| lstrlen | _tcslen | strlen | strlen | wcslen | (*2) |
| - | _tcsclen | strlen | _mbslen | wcslen | (*2) |
| - | _tcschr | strchr | _mbschr | wcschr | |
| - | _tcsstr | strstr | _mbsstr | wcsstr | |
| - | _tcstok | strtok | _mbstok | wcstok | |
| wsprintf | _stprintf | sprintf | sprintf | swprintf | |
| wvsprintf | _vstprintf | vsprintf | vsprintf | vswprintf | |
(この表の読み方) 同じ行には同じ働きをする関数を載せています。例えば lstrcat 関数と _tcscat 関数は同じ働きをする関数です。_tcscat 関数は,_MBCS が定義済の時 _mbscat に,_UNICODE が定義済の時 wcscat に,それ以外の時 strcat に等価です。
(*1) 例えば _mbsncmp("あい", "あイ", 2) の値は -1,_mbsnbcmp("あい", "あイ", 2) の値は 0 です。
(*2)-(1) 例えば strlen("abcあいう") の値は 9,_mbslen("abcあいう") の値は 6 です。
(*2)-(2) wcslen は UTF-16 のサロゲートペアを考慮しません。例えば wcslen(L"𢌞り道") の値は 4 です。
TEXT マクロ
文字セットの設定に応じて文字/文字列リテラルに接頭辞 L を付ける,TEXT(...) というマクロがあります。
#ifdef UNICODE
#define __TEXT(quote) L ## quote // 接頭辞 L を付ける
#else
#define __TEXT(quote) quote
#endif
#define TEXT(quote) __TEXT(quote)例えば TEXT("hello") という記述は,UNICODE が定義済ならば L"hello" に,未定義ならば "hello" に置換されます。
また,TEXT(...) マクロと同様の働きをするマクロに,_T(...) マクロ と _TEXT(...) マクロがあります。
#ifdef _UNICODE
#define __T(x) L ## x
#else
#define __T(x) x
#endif
#define _T(x) __T(x)
#define _TEXT(x) __T(x)